Nsq Handler Runs Again Even Though Return True
Messaging Queue Comparison : NSQ and Apache Kafka

As the system grows bigger and bigger, for fugitive any single point of failure, ofttimes we switch from the sometime monolithic to micro-service compages. By dividing the application into smaller independent units, the interaction count between each unit will abound significantly.
Messaging queue offers another mode to communicate and coordinate asynchronously particularly in this decoupled unit while improving performance, reliability, and scalability. The component which adds the message to the queue is chosen producer while the component which retrieves the message and procedure it called a consumer. Consumer and producer doesn't collaborate direct and uses the broker as the one that usually manages the queue.
Apache Kafka and NSQ is the example of the messaging queue which currently actually attracts my own interest.
So let's go into it.
ane. NSQ
NSQ is a realtime distributed messaging platform which is a successor from simplequeue.
The core component of the NSQ is consist of :
- nsqd is the daemon that receives, queues, and delivers message to client.
- nsqlookupd is the daemon that manages topology information.
Clients query nsqlookupd to detect nsqd producers for a specific topic and nsqd nodes broadcasts topic and aqueduct information. - nsqadmin is a Web UI to view aggregated cluster stats in realtime and perform various authoritative tasks.
NSQ offers :
- High-availability topology that minimizes SPOF.
Increase the availability by setting upward multiple instances for nsqd and nsqlookupd. - Guarantees that the message is delivered at least once.
- Certain caste of persistence. The message is stored until the consumer sends the finish point.
- Piece of cake to configure
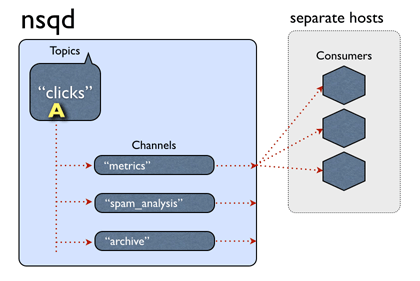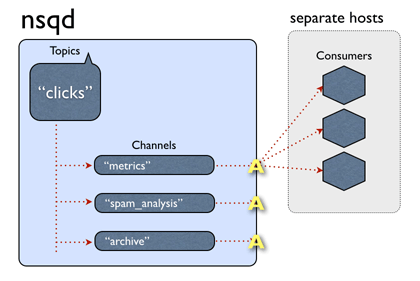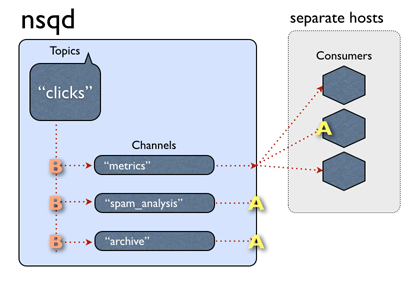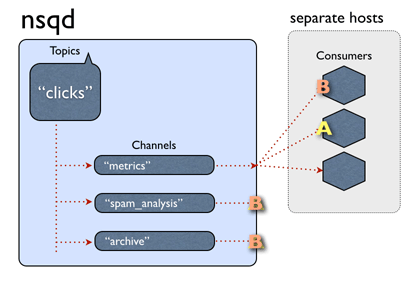
A single nsqd case is designed to handle multiple streams of data at once. Streams are called "topics" and a topic has 1 or more "channels". Each channel receives a copy of all the messages for a topic.
Both topics and channels are non pre-configured. Topics are created on first publish on the named topic or by subscribing channel on the named topic. Channels are created on the commencement apply of subscribing to the named aqueduct.
and both buffer data independently of each other.
A channel generally does have multiple clients connected and each message will be delivered to a random client
There are things to re-consider for the NSQ such every bit :
- The topology you are using volition always impact the reliability
Using only single instance will make it more prone to single bespeak of failure. NSQ is designed to be used for multiple instances. - When server NSQD crashes ungracefully, in that location might be a dataloss. Since there is no built-in replication.
- Unordered message
Since all of nsqd instances don't communicate between each other, unordered message its possible occurrence. - Duplicated message. Any case of consumer time out, NSQ will do the re-queue for the message, creating the possibility of the duplicate bulletin.
two. Apache Kafka
Comparing Kafka Streaming Platform to a messaging system such as NSQ is not an apple tree to apple comparison. Then what we will go through is simply the Kafka Messaging System.
Kafka said that they have a better throughput compared to other messaging queues. Supported by built-in partitioning and replication also fault tolerance, making information technology one of the reliable messaging organisation.
A topic is a category or feed proper noun to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can accept nil, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
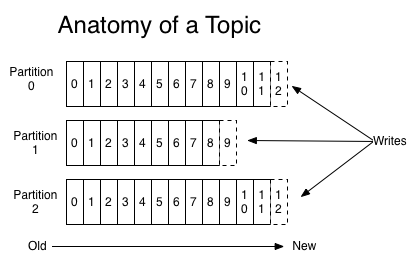
Each segmentation is an ordered, immutable sequence of records that is continually appended to a structured commit log. The records in the partitions are each assigned a sequential id number chosen the offset that uniquely identifies each tape within the partition.
The Kafka clusters persist all the records whether they have been consumed or not using a configurable memory period. For example, If we set the retention period for five days, then the bulletin will nevertheless persist for five days later on it has been published and still available for consumption.
Same as other messaging systems which consists of Producer and Consumer. Kafka has a unique mode of how both of these works :
- Producer
Publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This tin be done in a round-robin mode simply to balance load or it can be done according to some semantic partitioning function (say based on some key in the record).
- Consumer
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to i consumer instance within each subscribing consumer grouping. Consumer instances tin can exist in divide processes or on separate machines.
If all the consumer instances have the aforementioned consumer group, and so the records will effectively be load balanced over the consumer instances.
If all the consumer instances take different consumer groups, then each record will be circulate to all the consumer processes.

3. Comparison
Both messaging queue have a unique way of defining their architecture and how their banker works, only in several points, this might be a consideration which platform yous would choose :
- Availability
If the NSQD server crashes ungracefully, in that location might be a possible dataloss.
Kafka has a build-in replication and partitioning which make it accept a higher availability and reliability. with replication gene Due north, Kafka could tolerate Northward-1 server failures without losing any records.
To cater to this kind of problem, we could create redundant NSQD pairs on a divide host that receive the verbal same copies of the message.
- Persistence
NSQ will delete the bulletin if the consumer take already send the terminate indicate for the message.
Kafka has some other rule by setting the retentiveness whether it is time based or size based, but the bulletin is still persist after a sure specified time/size from the moment they are published.
- Replay-able letters
Since Kafka have the persistence storage system of the records, they provide the adequacy of replaying the message over and over again as long as it is notwithstanding stored.
- Gild of the bulletin
Since multiple instances of NSQD doesn't communicate with each other, there are always a possibility of an unordered message. While Kafka maintain each of their partition every bit an ordered sequence of records, Kafka will always provide an exact society of the message in a partition.
iv. Similarity
Both of NSQ and Kafka is quite a feats compared to others traditional message banker, Since both of them using Publish/Subscribe pattern and the manner the Kafka'southward Consumer Grouping have similarities with the NSQ's Channel system.
Nevertheless both of them provide a much more reliability, scalability, and persistence in their own caste.
5. In My Humble Opinion
For an open source messaging queue, NSQ provides quite a magnificent architecture and utilise-case, While on the other paw, Kafka provides much more sturdy platform from persistence, reliability and availability.
On this example, Which platform do you choose is based on only this one question.
Is dataloss is acceptable to you ?
If the respond is no, so Kafka is the answer.
Some other opinion of mine, If your organisation is already in Coffee and might interest in implementing Kafka, Then Kafka's streaming platform might be a consideration to think about.
Yep, the Streaming Platform is much pricier than the Messaging system. Simply seeing how information technology works, makes me really remember about how much the possibilities alee by implementing everything every bit a stream, non only equally a singular tape of letters.
Equally always, we have an opening at Tokopedia.
We are an Indonesian engineering company with a mission to democratize commerce through engineering and help everyone accomplish more.
Notice your Dream Job with us in Tokopedia!
https://world wide web.tokopedia.com/careers/
https://kafka.apache.org/
https://nsq.io/
Source: https://levelup.gitconnected.com/messaging-platform-comparison-nsq-and-apache-kafka-60f96f7466b1
0 Response to "Nsq Handler Runs Again Even Though Return True"
Post a Comment